
[AI 101 시리즈 ①] AI 초보자 필독! 인공지능의 정의부터 역사까지 – 튜링부터 ChatGPT까지의 70년 여정
핵심 한 문장
“인공지능은 지난 70년 동안 불가능의 영역을 계속 깨왔고, 지금 ChatGPT가 깬 경계는 인류가 ‘똑똑함’이라고 믿었던 마지막 보루입니다.”
들어가며: “당신은 지금 AI와 대화하고 있습니다”
마지막으로 검색창에 무언가를 입력한 게 언제인가요? 아마 며칠 전이죠. 그사이 당신의 휴대폰은 몇십 개의 AI 모델을 돌렸습니다. 얼굴 인식으로 락을 풀고, 타이핑 중 다음 글자를 예측받고, 음성 검색을 했다면 그건 AI가 당신의 목소리를 이해한 거예요.
“AI가 너무 일상화되어서, 이제 우리는 AI를 쓰고 있다는 걸 잊고 있습니다.”
하지만 정확히 AI가 무엇인지, 언제부터 시작되었는지, 어떻게 이렇게까지 똑똑해졌는지를 아는 사람은 놀랍도록 적어요. 마치 스마트폰을 쓰면서 전자기학을 모르는 것처럼요.
이 글은 당신이 AI의 완전한 “큰 그림”을 얻을 수 있도록 설계되었습니다. 개념부터 역사, 현재, 미래까지—마치 시간 여행을 하듯이요.
📍 목차
- AI, ML, 딥러닝—도대체 뭐가 다른가?
- 1950년대: “기계도 생각할 수 있을까?”—튜링 테스트의 탄생
- 1956~1974년: AI의 봄—꿈과 현실
- 1974~1980년대: AI의 겨울—환상이 깨진 시대
- 1980~2000년대: 겨울에서 깨어나기—전문가 시스템부터 빅데이터까지
- 2012년: 딥러닝의 폭발—AlexNet이 던진 돌의 파문
- 2017~2023년: AI 르네상스—Transformer부터 ChatGPT까지
- 결론: 우리는 역사의 어느 지점에 있는가?
AI, ML, 딥러닝—도대체 뭐가 다른가?
먼저 헷갈리는 세 개의 용어부터 정리합시다.
AI(Artificial Intelligence, 인공지능)는 가장 넓은 개념입니다. “사람처럼 생각하는 기계”라는 뜻이죠. 체스를 두는 프로그램도 AI고, 당신이 지금 보는 유튜브 추천도 AI입니다. 규칙 기반의 단순한 프로그램부터 ChatGPT까지 전부 AI의 범주에 들어가요.
머신러닝(Machine Learning, ML)은 AI의 부분집합입니다. “명시적으로 프로그래밍하지 않고, 데이터로부터 학습하는 AI”라는 뜻이에요. 예를 들어, 당신이 스팸 메일을 “스팸”이라고 표시할 때마다, 메일 필터는 “아, 이런 특징을 가진 메일이 스팸이구나”라고 학습합니다. 이게 머신러닝입니다.
딥러닝(Deep Learning)은 머신러닝의 부분집합입니다. “신경망(Neural Network)이라는 특수한 구조로 여러 겹의 층(layer)을 쌓아서 학습하는 머신러닝”이죠. 인간의 뇌 구조에서 영감을 받았기 때문에 “깊다(deep)”고 표현해요.
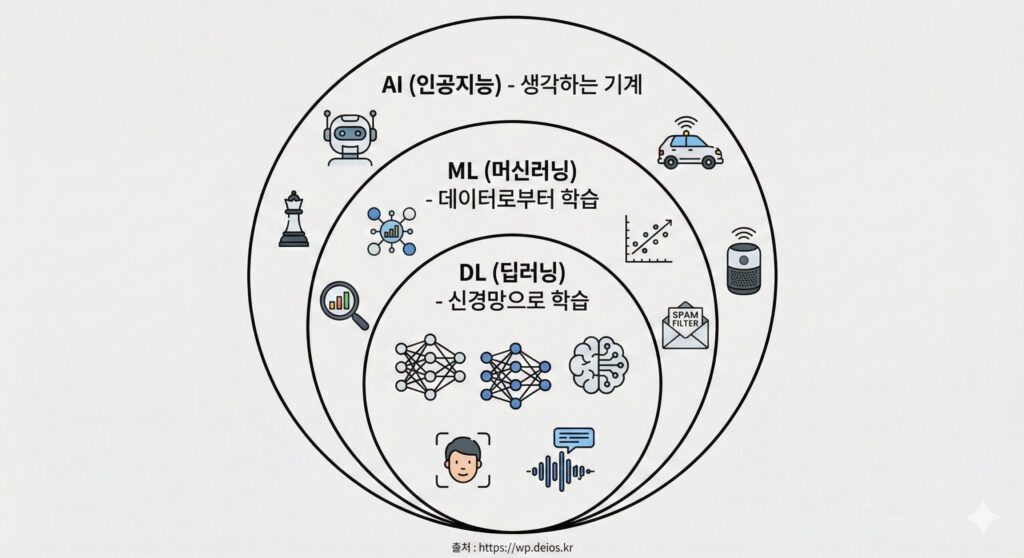
구체적인 예시로 이해해 봅시다:
- AI: 고양이 사진을 보고 “이건 고양이”라고 말하는 모든 시스템
- ML: 고양이 사진을 1만 개 보면서 “귀 모양, 수염, 발톱이 있으면 고양이”라고 스스로 규칙을 만드는 시스템
- 딥러닝: 신경망 구조로 고양이의 특징을 여러 겹의 층에서 처리해서 97% 정확도로 고양이를 인식하는 시스템
이제부터 말하는 “AI”는 이 세 개를 모두 포함한 개념으로 봐도 괜찮습니다. 맥락에 따라 더 정확히 구분할 테니까요.
[표 삽입 예정] AI vs ML vs 딥러닝 비교표
- 범위: 넓음 ← AI / ML / 딥러닝 → 좁음
- 학습 방식: 규칙 기반 ← → 데이터 기반
- 정확도: 낮음 ← → 높음
- 계산 자원: 적음 ← → 많음
1950년대: “기계도 생각할 수 있을까?”—튜링 테스트의 탄생
역사는 1950년, 영국 수학자 앨런 튜링(Alan Turing)의 한 장의 논문에서 시작합니다.
당시 컴퓨터는 ENIAC 같은 거대한 방 크기의 기계였어요. 튜링은 급진적인 질문을 던졌습니다: “기계가 생각할 수 있는가?”
그런데 이건 너무 철학적이고 정의하기 어렵다고 생각했어요. 그래서 그는 더 실용적인 질문으로 바꿨습니다:
“우리가 기계와 텍스트로 대화할 때, 그게 기계인지 사람인지 구분할 수 없다면, 그 기계는 생각하는 것인가?”
이것이 바로 튜링 테스트(Turing Test)입니다.

심사자: "2+2는?"
상대A (사람): "4입니다"
상대B (기계): "4입니다"
심사자: "아, 2+2는 뭔데 이렇게 쉬워?"
상대A: "음... 거기엔 철학적 의미가 있어요"
상대B: "네, 2와 2의 합은 수학적으로 4입니다"
심사자가 느끼는 감정: "음, 상대 A가 사람 같은데? 왜 상대 B는 좀 로봇같지?"그런데 여기서 중요한 건, 튜링은 기계가 진짜로 “생각”하는지는 신경 쓰지 않았다는 거예요. 행동만 같으면 충분하다고 본 거죠. 이걸 “행동주의적 접근(Behaviorism)“이라고 부르는데, 이것이 AI 역사 전체를 지배한 철학입니다.
역사적 의미:
| 항목 | 내용 |
|---|---|
| 발표 연도 | 1950년 (Computing Machinery and Intelligence) |
| 핵심 질문 | 기계도 생각할 수 있는가? |
| 답변 방식 | 행동이 같으면 충분하다 |
| 영향력 | 이후 70년간 AI 연구의 철학적 기초 |
1956~1974년: AI의 봄—꿈과 현실
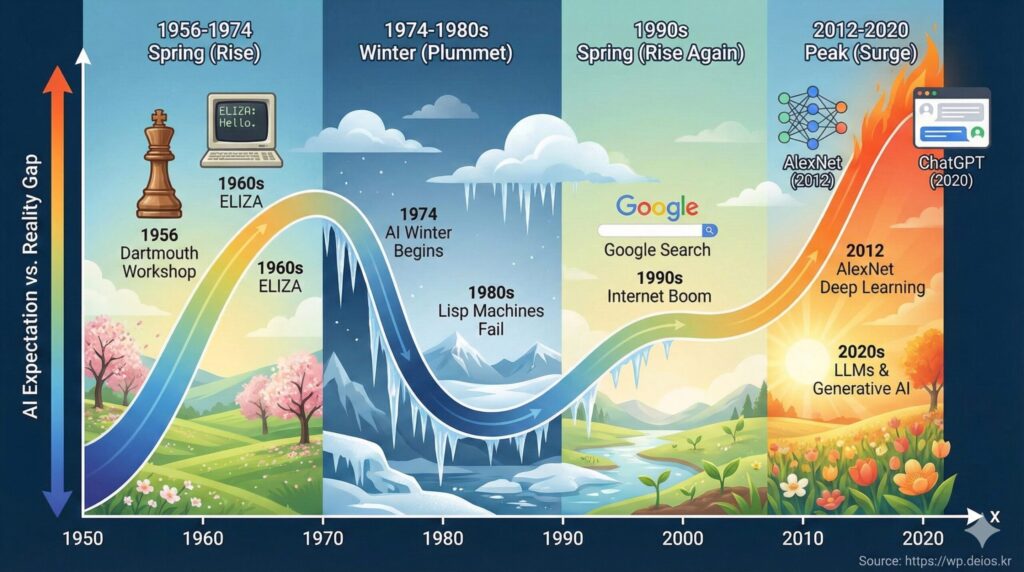
1956년 여름, 미국 다트머스(Dartmouth)에서 한 회의가 열렸습니다.
당대의 천재 수학자, 과학자들이 모였어요. 존 매카시(John McCarthy), 마빈 민스키(Marvin Minsky), 나다니엘 로체스터(Nathaniel Rochester) 등. 이들은 6주간 모여서 “기계 지능(Machine Intelligence)”을 연구했습니다.
이 회의의 결론은 낙관적이었어요: “만약 우리가 충분한 자금을 받는다면, 몇 년 안에 인간 수준의 지능을 가진 기계를 만들 수 있을 겁니다.”
이 예측이 얼마나 틀렸는지는 후에 봐요.
당시 만들어진 성과들:
- 1956년: 초기 체스 프로그램 — 규칙 기반으로 체스 움직임 계산
- 1966년: ELIZA — 정신과 의사처럼 대화하는 프로그램 (실제로는 규칙 기반 문장 변환)
- 1974년 직전: 전문가 시스템(Expert System) — 의료, 법률 등 특정 분야의 전문가 지식을 규칙화
ELIZA의 예시:
사람: “내 어머니는 나를 싫어합니다”
ELIZA: “당신의 어머니가 당신을 싫어한다면, 그건 왜일까요?”
사람: “모르겠어요”
ELIZA: “모른다는 것이 당신의 문제를 해결하는 데 도움이 될까요?”
마치 심리 치료사 같은 느낌이죠? 하지만 ELIZA는 실제로 아무것도 이해하지 못했습니다. 단지 입력 문장의 구조를 분석해서 정해진 규칙에 따라 대답했을 뿐이에요. 그런데도 많은 사람이 ELIZA가 정말로 자신의 이야기를 “이해”한다고 생각했습니다.
이것을 “ELIZA 효과“라고 부르는데, 이것이 AI 역사에서 첫 번째 교훈입니다: “우리는 기계가 우리를 이해한다고 생각하기를 원한다.”
이 시대의 특징:
- 규칙 기반 AI (Rule-Based AI)
- 전문가의 지식을 프로그래머가 하나하나 입력
- 매우 제한된 작업만 가능 (체스, 특정 분야 진단 등)
- 하지만 사람들의 기대치는 무한대
1974~1980년대: AI의 겨울—환상이 깨진 시대
현실은 시계집 쥐 같았습니다.
1956년의 낙관적인 예측은 모두 빗나갔어요. 왜일까요?
① 계산 능력의 한계
규칙 기반 AI는 가능한 모든 경우를 계산해야 했어요. 예를 들어 체스는 한 게임에 가능한 수가 약 10^120개입니다. 우주의 입자 개수가 10^80개인데, 체스의 가능성이 더 많다는 뜻이에요.
“컴퓨터가 빨라지면 해결되지 않을까?”라고 생각할 수도 있지만, 이건 “조합 폭발(Combinatorial Explosion)”이라고 불리는 근본적인 문제였어요.
② 지식 표현의 불가능성
“내 어머니는 인간이다”라는 문장을 컴퓨터가 이해하게 하려면 몇 줄의 코드가 필요할까요? 간단한 것처럼 보이지만, 세상의 모든 지식을 규칙으로 만드는 것은 사실상 불가능했어요.
③ 자금 지원 중단
연구자들의 과장된 약속, 기대와 현실의 괴리가 심해지자, 정부와 기업들이 AI 연구에 손을 뗐습니다. 특히 1974년과 1980년 두 차례의 AI 겨울이 찾아왔어요.
이 시대의 통설:
“AI 연구는 실패했다. 기계가 인간의 지능을 따라갈 수는 없을 것 같다.”
이것을 “AI 웰터(AI Welt)” 또는 “디스일루셔닝(Disillusionment)”이라고 부릅니다.
하지만 이 겨울에도 조용히 진전이 있었어요.
1980~2000년대: 겨울에서 깨어나기—전문가 시스템부터 빅데이터까지
1980년대: 전문가 시스템(Expert System)의 재출현
“우리가 모든 지식을 컴퓨터에 넣을 수 없다면, 특정 분야의 전문가 지식만이라도 넣어보자”라는 전략으로 나아갔어요.
- 의료 진단: 증상을 입력하면 질병 추측
- 법률: 판례를 입력하면 판결 예측
- 지질학: 지형 데이터를 입력하면 유전 가능성 예측
이런 시스템들은 매우 특정한 분야에서는 정말 잘 작동했어요. 1980년대와 1990년대 초반, 기업들은 AI(실제로는 전문가 시스템)에 수십억 달러를 투자했습니다.
그런데 또 문제가 생겼어요: 규칙이 너무 많아지니까 유지보수가 불가능했던 겁니다.
1990년대 말~2000년대: 패러다임 전환—데이터의 힘
이 시대에 중요한 변화 세 가지가 있었어요:
- 인터넷의 폭발 (1995~2005년)
- 웹 페이지가 수십억 개가 생김
- 데이터가 엄청나게 많아짐
- 컴퓨터 성능 향상 (무어의 법칙)
- CPU, GPU 성능이 기하급수적으로 증가
- 메모리가 저렴해짐
- 통계적 접근의 부상
- 규칙 기반 → 데이터 기반으로 전환
- “규칙을 만들지 말고, 데이터에서 패턴을 찾자”
구글의 탄생 (1998년):
래리 페이지와 세르게이 브린은 “인터넷의 모든 페이지를 순위 매기는 알고리즘”을 만들었어요. 이것이 PageRank 알고리즘인데, 이것은 이제 와서 보면 머신러닝의 초기 형태였습니다.
이 시대의 AI들은 여전히 “딥”하지는 않았어요. 하지만 규칙 기반에서 데이터 기반으로의 전환이 일어났고, 이것이 이후의 모든 발전의 기초가 되었습니다.
2012년: 딥러닝의 폭발—AlexNet이 던진 돌의 파문
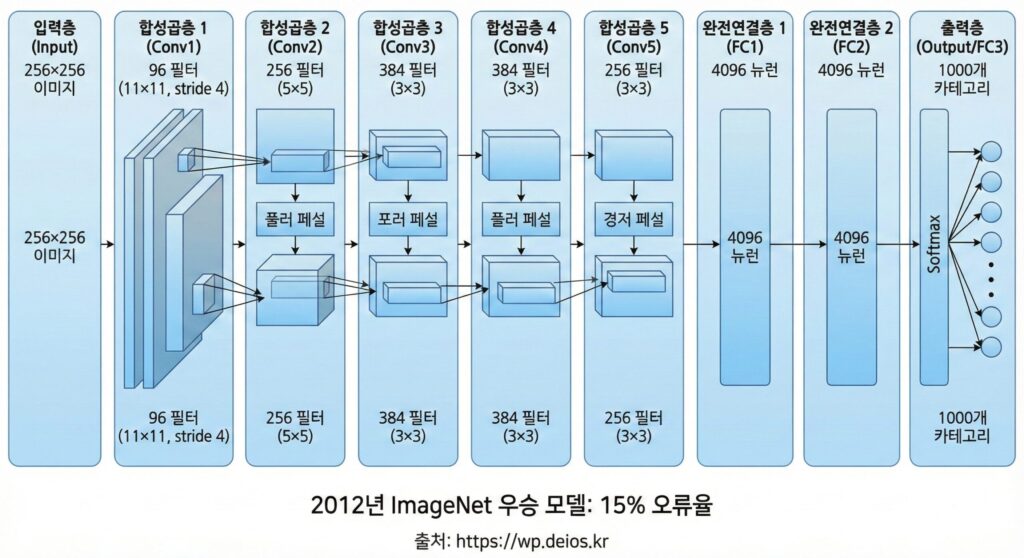
2012년 가을, 토론토 대학의 제프리 힌튼(Geoffrey Hinton) 교수팀은 이미지 인식 대회(ImageNet)에서 압도적인 성과를 냈습니다.
그 해의 오류율은 26%였어요. 그런데 힌튼 팀의 AlexNet은 15%의 오류율로 우승했습니다.
“어? 11%포인트 개선이 뭐 그리 대단한가?”라고 생각할 수 있지만, 이건 그때까지의 개선 속도의 2배 수준이었어요.
그리고 더 중요한 것은 방법론이었습니다: AlexNet은 깊은 신경망(Deep Neural Network)으로 이미지를 인식했습니다. 이것은 과거 30년간 외면받았던 기술이었어요.
왜 갑자기 복구되었을까요?
세 가지 이유:
- GPU의 등장 — NVIDIA의 GPU가 신경망 학습을 가능하게 함
- 빅데이터 — ImageNet에 100만 개의 라벨 이미지
- 알고리즘 개선 — ReLU 활성화 함수, 드롭아웃 등 새로운 기법
AlexNet의 구조:
입력 이미지 (256×256 픽셀)
↓
[합성곱층 1] (conv) - 96개 필터
[맥스풀링층 1]
↓
[합성곱층 2] - 256개 필터
[맥스풀링층 2]
↓
[합성곱층 3~5] - 더 깊어짐
↓
[완전연결층] (fully connected)
↓
[소프트맥스] (1000개 카테고리 확률)
↓
출력: "이건 개다" (99% 확률)이건 간단한 구조처럼 보이지만, 이전까지 사람들이 신경망은 “너무 깊으면 학습이 안 된다”고 생각했거든요. AlexNet은 8개의 층이라는 “충격적인” 깊이로 우승했어요.
이 시대의 의미:
Before AlexNet (2011년):
- 이미지 인식 오류율: 26% (기존 방법)
- 신경망은 "구식 기술"
After AlexNet (2012년):
- 이미지 인식 오류율: 15%
- 신경망은 "미래의 기술"
변화: -11%포인트 개선 = AI 르네상스의 시작이후 매년 ImageNet 우승 모델들이 나왔어요: VGGNet (2014), ResNet (2015), DenseNet… 그리고 각 해마다 성능이 계속 개선되고 있습니다.
2017~2023년: AI 르네상스—Transformer부터 ChatGPT까지
2017년 6월, 구글의 연구팀은 논문 하나를 공개했습니다.
제목: “Attention Is All You Need” (Attention이 전부다)
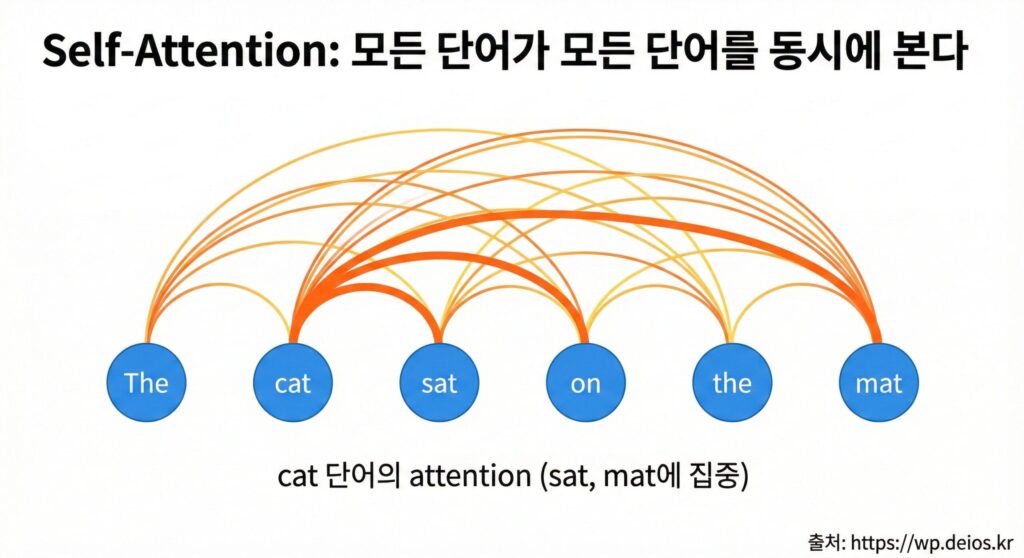
이 논문의 핵심은 Transformer라는 새로운 아키텍처였어요. 이전까지 자연어 처리는 RNN(Recurrent Neural Network)이 지배했는데, Transformer는 “한 번에 모든 단어를 동시에 처리”했습니다.
왜 이게 중요할까요?
RNN의 문제:
- “The cat sat on the mat” 문장을 읽을 때
- “The” → “cat” → “sat” → … → “mat”
- 한 단어씩 순차적으로 처리 (느림, 병렬화 불가)
Transformer의 해결:
- 모든 단어를 동시에 볼 수 있음 (병렬화 가능)
- “The”가 “mat”과의 관계도 직접 계산 가능
- 10배 이상 빠름
[다이어그램 삽입 예정] RNN vs Transformer 구조 비교
- RNN: 순차 처리, 느림, 기울기 소실 문제
- Transformer: 병렬 처리, 빠름, Self-Attention 메커니즘
Transformer의 등장 이후, NLP 분야는 폭발했습니다.
2018년: BERT의 탄생
구글의 BERT(Bidirectional Encoder Representations from Transformers)는 “양방향 언어 이해”에 혁명을 일으켰어요.
이전까지의 언어 모델은 “다음 단어 예측” 같은 한 방향만 봤는데, BERT는 문맥 앞뒤를 모두 봐서 단어의 의미를 더 정확하게 이해했어요.
2018년: GPT-1의 탄생
OpenAI의 GPT(Generative Pre-trained Transformer)는 “텍스트 생성”에 특화했어요. BERT와 달리, GPT는 단방향이지만 “창의적인 텍스트를 생성할 수 있었습니다”—꼭 사람처럼요.
그리고 규모가 계속 커졌습니다:
| 모델 | 파라미터 수 | 출시 연도 | 특징 |
|---|---|---|---|
| GPT-1 | 1.17억 | 2018 | 기초 생성형 AI |
| GPT-2 | 15억 | 2019 | 텍스트 생성 개선 |
| GPT-3 | 1,750억 | 2020 | Few-shot 학습 가능 |
| GPT-3.5 | 추정 1,750억+ | 2022 | 안정적이고 정렬됨 |
| GPT-4 | 추정 1조+ | 2023 | 멀티모달 (텍스트+이미지) |
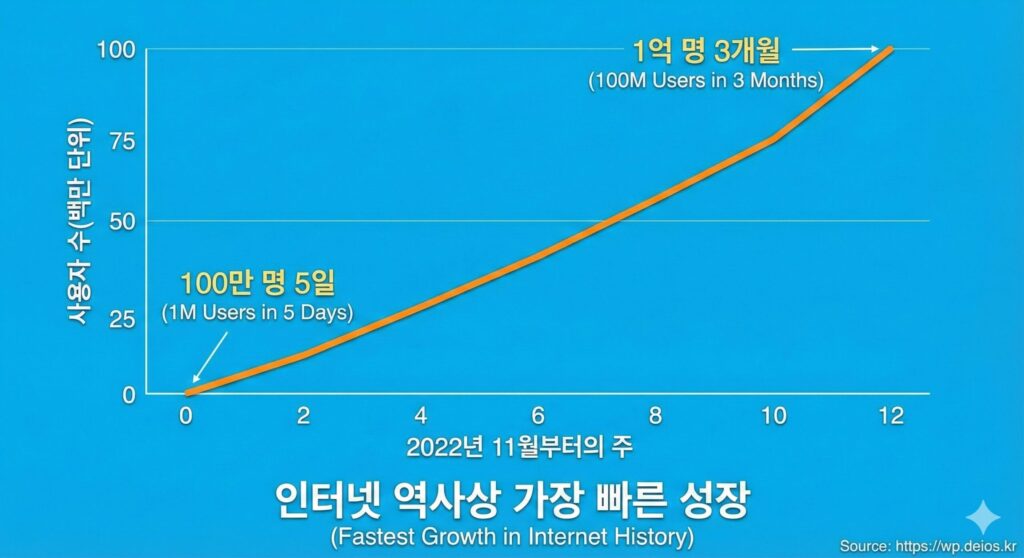
2022년 11월: ChatGPT의 폭발
OpenAI가 ChatGPT를 공개했을 때, 세상이 바뀌었어요.
- 5일 만에 100만 명 사용자 달성 (인스타그램: 25일, 페이스북: 10개월)
- 3개월 만에 1억 명 (인터넷 역사에서 가장 빠른 성장)
- 일반인들이 처음으로 AI의 “능력”을 직접 경험
ChatGPT 이전까지, AI는 “기술자의 도구”였어요. 하지만 ChatGPT는 “할머니도 쓸 수 있는 AI”였습니다.
ChatGPT의 예시:
사용자: “Python으로 간단한 게임을 만드는 코드를 줄 수 있어?”
ChatGPT:
import random
number = random.randint(1, 100)
guess = None
while guess != number:
guess = int(input("1에서 100 사이의 숫자를 맞혀보세요: "))
if guess < number:
print("더 크습니다!")
elif guess > number:
print("더 작습니다!")
else:
print("맞았습니다!")“와, AI가 코드를 짜네?”라는 반응이 전 세계적으로 퍼졌어요.
[이미지 삽입 예정] ChatGPT 사용자 성장 그래프
- 가로축: 출시 이후 주(weeks)
- 세로축: 사용자 수 (백만 단위)
- 선: 수직 상승하는 곡선
2023~2024년: AI 경쟁의 가속화
ChatGPT의 성공 이후:
- Google Gemini (2023): “더 똑똑한 AI”를 표방
- Anthropic Claude (2023): “더 안전한 AI”를 강조
- Meta Llama (2023): 오픈소스 AI 공개
- Mistral (2023): 유럽의 오픈소스 AI
- Apple Intelligence (2024): 디바이스 내 AI
각 회사가 자신만의 방식으로 AI를 개선하고 있어요.
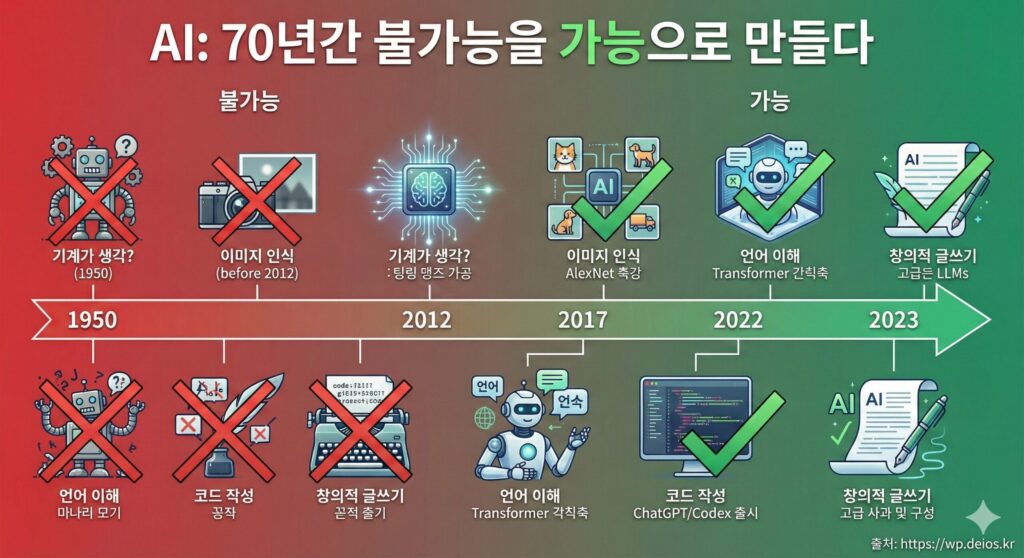
결론: 우리는 역사의 어느 지점에 있는가?
70년의 역사를 한 문장으로 요약하면:
“AI는 불가능이라고 생각했던 것들을 계속 가능하게 만들어 왔다.“
| 시대 | 불가능 → 가능 |
|---|---|
| 1950년대 | “기계가 생각할 수 있을까?” → 튜링 테스트 등장 |
| 1970년대 | “체스 같은 복잡한 게임을 할 수 없다” → (30년 뒤) Deep Blue가 카스파로프 이김 |
| 1990년대 | “수억 개의 웹페이지를 정렬할 수 없다” → 구글 탄생 |
| 2010년대 | “사진 속의 고양이를 인식할 수 없다” → AlexNet이 15% 오류율로 인식 |
| 2020년대 | “AI가 글을 창의적으로 쓸 수 없다” → ChatGPT가 에세이 작성 |
그렇다면 다음은?
혹자는 “AI가 모든 인간의 일을 대체할 것”이라고 공포심을 드러내고, 또 다른 누군가는 “AI는 결국 한계에 부딪힐 것”이라고 회의적입니다.
하지만 역사가 말해주는 건 다릅니다: “우리의 예측은 항상 틀렸다.”
1956년 다트머스 회의의 과학자들은 “몇 년 안에 인간 수준의 지능을 만들 것”이라고 했지만, 70년이 지난 지금도 우리는 “진정한 일반 지능(AGI)”을 만들지 못했어요. 동시에 아무도 예상하지 못한 방식으로(GPU + 빅데이터 + 신경망), 우리는 ChatGPT를 손에 쥐고 있습니다.
D’s World AI 101 시리즈는 이 여정의 기초입니다.
다음 포스트부터, 우리는:
- AI가 어떻게 학습하는지 (AI는 어떻게 학습할까? 머신러닝의 3가지 학습 방법 완벽 가이드)
- 데이터를 어떻게 준비하는지
- 신경망을 어떻게 설계하는지
- 최신 모델들(Transformer, BERT, GPT)이 어떻게 작동하는지
하나하나 파헤칠 거예요.
지금까지 “AI란 뭔가?”라는 물음에 “말로 설명하기 어려운 뭔가”라고 대답했다면, 이 시리즈를 마친 후에는 “AI가 뭐고, 어떻게 돌아가고, 어디로 가는지” 명확하게 설명할 수 있을 겁니다.
🔗 외부 참고 자료
- Turing, A. M. (1950). “Computing Machinery and Intelligence” — AI의 철학적 기초
- IEEE: Brief History of Artificial Intelligence — AI 역사의 공식 기록
- Hinton et al. (2012). ImageNet Classification with Deep Convolutional Neural Networks — AlexNet 원본 논문
- Vaswani et al. (2017). Attention Is All You Need — Transformer 원본 논문
- Devlin et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers — BERT 원본 논문
- OpenAI Blog: Language Models are Unsupervised Multitask Learners — GPT 시리즈
- Nature: AI의 미래에 대한 종합 분석 — 학술지 Nature의 AI 특집
- AI 초보자 필독! 인공지능의 정의부터 역사까지 – 튜링부터 ChatGPT까지의 70년 여정
축하합니다! 🎉
당신은 이제 “AI란 무엇인가?” 라는 질문에 명확하게 답할 수 있게 되었습니다. 다음 포스트에서는 AI가 “어떻게 학습”하는지를 파헤칠 거예요.
“D’s World AI 101 시리즈”에서 당신의 AI 여정이 시작됩니다. 🚀
이 글이 도움되었나요? 댓글에 “가장 흥미로웠던 AI 역사 사건”을 남겨주세요. 더 깊이 있는 콘텐츠를 준비하겠습니다!